- 事象
「確率」 の論は,「事象」 から始まる。
「事象」 は,形式が一様ではない。
即ち,数学に乗せるときの形式は,一様にはならない。
ここでは,話を簡単にするために,つぎの形式の事象を扱う:
「これは,こう」
<これ>に対する<こう>は,一意
即ち,<これ>に対する<こう>は,関数の関係。
また,「これは,こう」 を,簡単に,(t, x) と書くことにする。
事象の例
「人の体重」
この場合は,(t, x) の t には人の ID が,x には体重が,それぞれ入る:
(人1, 52kg), (人2, 45kg), ‥‥‥
「コインを放り投げて出る表裏」
この場合は,(t, x) の t には放り投げ行為の ID が,x には表か裏が,それぞれ入る:
(行為1, 表), (行為2, 裏), ‥‥‥
- 大数の法則
事象のタイプを1つ固定して考える。
事象は,たくさん集めると,1つの傾向を現すようになる (「てんでバラバラ」 も含めて)。
これを 「大数の法則」 と謂う。
そこで,この傾向を捉えることを問題にする。
これが,「確率」 の話になる。
- 標本空間
傾向を捉えるために,サンプル (標本) を集める。
この集合を 「標本空間」 と謂う。
これを Ω で表そう。
Ω の要素は,(t, x) の形をしている ── 「これ(t) は,こう(x)」。
Ω は,集合であるが,関数になっている:
Ω : t├─→ x
(「これは,こう」)
<これ>の集合をT,<こう>の集合をXで表そう。
- 分布
事象の傾向を表す方法として先ず思いつくのが,つぎの対応をつくること:
|Ω−1|:X → 自然数
x ├─→ | Ω−1(x) |
<こう>に対する<これ>の数の分布をつくるわけでえある。
この分布が,事象の傾向を表すというわけ。
- 確率
| Ω−1(x) | が大きい x ∈ X は,「現れやすい」 と見ることができる。
──逆に,| Ω−1(x) | が小さい x ∈ X は,「現れにくい」 。
この 「現れやすい・現れにくい」 を,「確率」 のことばで捉える。
即ち,各x ∈ X に対し,「x である確率」 をつぎのように定義する:
P(x) = | Ω−1(x) | / | Ω |
そしてこれは,
<こう>に対する<これ>の確率の分布
を意味する関数Pを定義していることになる:
P : X → 実数
x├─→ | Ω−1(x) | / | Ω |
- 度数分布と確率分布
こうして,<こう>に対する<これ>の分布が,
|Ω−1| :X → 自然数
P :X → 実数
の2つで表現されることになった。
|Ω−1| は 「度数分布」 と呼ばれる。
P は 「確率分布」 と呼ばれる。
- Xを数の集合に限定
ここから以下は,Xを数の集合とする。
実用上,数は離散で考える。
Xの要素を数にすることで,何が変わるか?
数の順序を以て,横軸が数のグラフがつくれる:
|Ω−1| は,縦軸が<これ>の数
P は,縦軸が<これ>の確率
そして,この後に述べる 「期待値」, 「分散」, 「標準偏差」 といったものを考えられるようになる。
例1.「サイコロ1個を振って出る目」
Ω = { (試行1, 3), (試行2, 5), ‥‥, (試行n, 1) }
確率分布は,

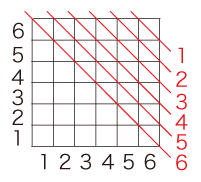
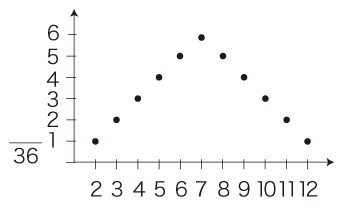
例2.「サイコロ2個を振って出る目の和」
Ω = { (試行1, 8), (試行2, 4), ‥‥, (試行n, 10) }
確率分布は,
P(2) = P(12) = 1/36
P(3) = P(11) = 2/36
P(4) = P(10) = 3/36
P(5) = P(9) = 4/36
P(6) = P(8) = 5/36
P(7) = 6/36
|
数え方
グラフ
- 「確率変数」
慣行では,ここで 「確率変数」 というものが登場する。
P(2) のような表現では収まりが悪いと考えたためか,
P(X=2)
と書き,Xを 「確率変変数」 と呼ぶのである。
この表記は,数学の文法からの逸脱である。
そしてこの逸脱は,そのまま学習者の躓きになる。
学習者は,テクストを神聖・不可侵と定める者なので,このナンセンスな表記をわかるようにならねばと思う。
そして当然,挫折する。
教える者は,「確率変数」 が
分析して理解に至るというものではなく,
ただ慣れるもの
だということを,教えてやらねばならない。
とはいえ,「確率変数」 は,すっかり定着していて,これを使わないことが却って学習者を困らせるということにもなる。
そこで本テクストも,以上のように理を示した上で,この慣用表記を適宜用いることにする。
実際,
P : X → 実数
x├─→ | Ω−1(x) | / | Ω |
の 「X」 は,文字は何でもかまわないのだが,「確率変数X」 に合わせるために,使ってきたのである。
- 「期待値」
事象 「これ(t)はこう(x)」 を無作為に現し,それの x を得点とする。
ここでつぎの問いを立てる:
どのくらいの得点が期待できるか?
これは,確率分布 P から導かれるのでは?
そして,つぎの 「期待値」 の定義になる:
E = Σ{ n × P(n) | n ∈ X }
例1.「サイコロ1個を振って出る目」
P = { (1, 16), (2, 1/6), ‥‥, (6, 1/6) }
E =1× 1/6 + ‥‥‥ +6× 1/6
= (1+ ‥‥‥ +6) / 6
= 3.5
- 「分散・標準偏差」
つぎの2つの確率分布は,ともに期待値が 3.5 である:
「偏りのないサイコロ」
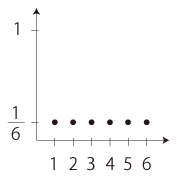
P(1)=P(2)=P(3)=P(4)=P(5)=P(6)=1/6
E =1× 1/6 +2× 1/6 +3× 1/6
+4× 1/6 +5× 1/6 +6× 1/6
= 3.5
「3, 4 に偏りのあるサイコロ」
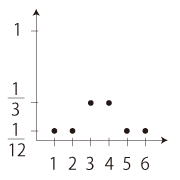
P(1)=P(2)=P(5)=P(6)=1/12, P(3)=P(4)=1/3
E =1× 1/12 +2× 1/12 +3× 1/3
+4× 1/3 +5× 1/12 +6× 1/12
= 3.5
しかし,実際の得点と期待値の近さは,2つで違うように見える。
即ち,得点は,後者の方が期待値に近くなりそうである。
こう思わせるのは,グラフの形である。
その形は,どう表現したらよいか?
この問いから,つぎの 「分散」 「標準偏差」 の定義がつくられることになった:
分散:
V = Σ{ (n − E)2 × P(n) | n ∈ X }
| 註: |
<2乗>は,
Σ{ (n − E) × P(n) | n ∈ X } = 0
となることへの対策。
|
標準偏差:
「サイコロ」 の2つの例では,分散・標準偏差がつぎのように違ってくる:
「偏りのないサイコロ」
V = (1ー3.5)2 × 1/6 + ‥‥‥ +(6ー3.5)2 × 1/6
=35/12
≒ 2.92
σ = √ V
= √ 2.92
≒ 1.71
「3, 4 に偏りのあるサイコロ」
V = (1ー3.5)2 × 1/12
+ (2ー3.5)2 × 1/12
+ (3ー3.5)2 × 1/3
+ (4ー3.5)2 × 1/3
+ (5ー3.5)2 × 1/12
+ (6ー3.5)2 × 1/12
≒ 1.58
σ = √ V
= √ 1.58
≒ 1.27
- 「正規分布」
確率分布の論は,「正規分布」 が1つのゴールになる。
ここまで論じてきた確率分布
P : X → 実数
は,Xが離散な数になっていた。
この P のグラフは,ヒストグラムにすることで,
X = 実数
積分が1
のグラフに変えられる。
さらに,つぎのイメージを持てる:
X の区間を細かくすることで,
積分=1を保ったまま,
P が連続関数に近づく
この P の理想形を考えたのが,正規分布である。
正規分布は,便利なツールとして,良い意味でも悪い意味でも 「悪用」 される。
実は,確率分布は,つくるのが簡単というものではない:
標本の収集・編集は,簡単ではない
きれいな分布が現れるとは限らない
そんなとき,「正規分布が成立する」と言って,これを使う手がある。
そしてこれが高じると,確率の話なのかどうか疑わしいことに,適用することになる。
|