その多様は,基本的には,Aの存在階層の多様と対応している。 そして存在階層は,基本的に,スケールの多様と対応している。 ひとは,自分が見たり聴いたり触ったりしているものを存在だと思っているが,そのものは,スケールを小さくしていくことによっても,大きくしていくことによっても,無くなる。 「ミクロ・マクロ」は,ものの見え方がスケールによって違うことを指すことばである。 このとき,ひとはたいてい,マクロはミクロに還元されると思っている。 さらに,マクロはミクロで説明されると思っている。 これを還元主義と謂う。 しかし還元主義は,数学のような演繹を方法論にして明示的に構築される体系にのみ成立するものである。 リアルな存在には,適用できない。 例えば,「雲」。 「雲=マクロ」に対するミクロは? 水滴? そうではない。 雲現象の要素になるミクロなものは,無限にある。 「ChatGPT =マクロ」は,雲よりは数学に近い? 数学に近そうだから,還元主義が成立する? そうはならない。 ミクロ (parameter, variant, algorism) からの演繹の体系ではないのである。 ── 「訓練」 がブラックボックスとして介在する。 そして説明に動員することになる要素は,実質的に無限になる。 ミクロによる説明は,つくれない。 例えば,ChatGPT につぎのように問う: 「文字列 "2ya0bdc7e" の文字数は? 」 ChatGPT は, 「9」と答える。 これを,ミクロ (parameter, variant, algorism) で説明することはできない。 存在の記述は,言語も違ってくる。 マクロ現象の記述には,マクロ言語を用いることになる。 「文字列 "2ya0bdc7e" の文字数は? 」の問いに対し ChatGPT が「9」と答えることに対する説明は, 「ChatGPT は "数える" の概念をもっており, そして "数える" を行う」 である。 ChatGPT は,Transformer を「脳」とした,「体」である。 (  オーケストレーション) オーケストレーション)
ここでは,「ChatGPT とは何か」 の問い対し,つぎの2つの存在階層を考えることにする: 2. Transformer のしくみ 以下,この2つの存在階層を概観しておく。 1. ChatGPT の行動 1. デフォルト 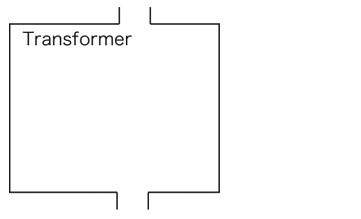 2. 起動 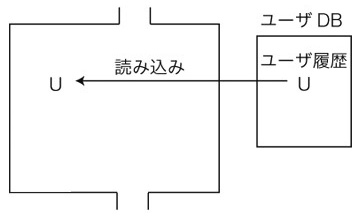
3. ユーザの入力テクストxに,応答テクストyを返す 
4. xとyを,Yに追加する: 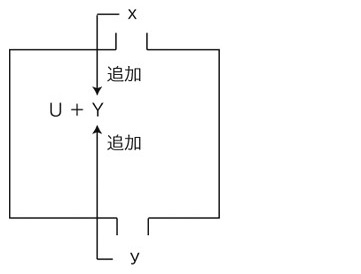
5. セッション終了: 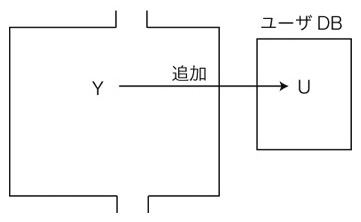
2. Transformer のしくみ 使用記号
Transformer の応答生成は,つぎのアルゴリズムになる:
↓トークン分割 [ t_1, ‥‥, t_m ] ↓対応するトークン点 [ x_1, ‥‥, x_m ] ┌→ [ x_1, ‥‥, x_m ] │ │ │ 生成終了?── YES ───→ 応答出力 │ │NO │ │← 位置エンコーディング加算 │ ↓ │ x_i^(1) = x_i ( i = 1, ‥‥, m ) │ x_i^(ℓ) │ ├─────┐ │ │ Self-Attention │ │ ↓ │ │ z_i^(ℓ) │ │ │← LayerNorm │ │← 加算 ─┘ │ │ │ ├─────┐ │ │ FFN │ │ ↓ │ │ z'_i^(ℓ) │ │ │← LayerNorm │ │← 加算 ─┘ │ ↓ │ x_i^(ℓ+1) │ x_i^(NL) │ ↓← Self-Attention, FFN │ o_i = x_i^(NL+1) │ ↓ │ logis │ ↓ │ [ p_1, ‥‥, p_m ] │ p_m : 「x_m の次は x_(m+1)」 │ │ └────┘m = m+1 ここで, ┌──────┼──────┐ ↓線型変換 ↓ ↓ Q_i = x_i W_Q K_i = x_i W_K V_i = x_i W_V └──┬───┘ │ ↓ │ α_i = sim( Q_i ; K_1, ‥‥, K_m ) │ │ │ └───┬──────┘ z_i = α_i V ↓← LayerNorm sim( Q_i ; K_1, ‥‥, K_m ) = softmax( Q_i (K_1)^T/√D, ‥‥ , Q_i (K_m)^T/√D ) ・FFN ↓ z'_i = σ( x_i W_1 + b_1) W_2 + b2 ↓← LayerNorm ・[ p_1, ‥‥, p_m ]
p_i = softmax( logits_i ) このアルゴリズムは,<"Training" モードの Transformer>のアルゴリズムのうちの「順伝播」を,ループさせたものである。 <"訓練 Training" モードの Transformer>は,トークンベクトルと各種重みの値を「逆伝播」のアルゴリズムで更新する。 これが, 「脳の成長」の意味になる。 この成長を止め ROM にしたのが,ChatGPT の Transformer 脳である。 ROM 化された Transformer は, m+1 番目のトークンは, ・TN次元数ベクトル p_m = ( p(1), ‥‥, p('TN) ) p( k ) ≈ 1 のとき,T( k ) を出力。 ユーザの入力テクストに対する応答テクストの出力は,「宇宙の出来事は決定論」と言うのであれば,決定論である。 しかしこの決定論は,複雑系の決定論。 複雑系の決定論は,「決定論」として考えることができない。 ChatGPT の動作は,決定論であって決定論ではない。 この押さえは,ChatGPT の論を地に足のついたものにする上で,ことのほか重要である。 |